Your service catalog is
already wrong.
Your AI agents are acting on it right now. NOFire AI derives your catalog from live production, so it reflects what is really running, not what someone declared six months ago.






Your catalog is always a step behind.
Backstage, Cortex, Compass, Roadie. Every catalog tool shares the same assumption: humans will keep it accurate. That assumption breaks by week two.
Stale by design
Catalog entries go out of date the moment a team restructures, a dependency shifts, or a new service ships. Nobody updates the YAML.
Incidents expose it
Your on-call rotation discovers the real service topology during the incident. The catalog was wrong. It always is.
Maintenance tax
Two to three engineers spend significant time keeping Backstage running: plugins, integrations, authentication, the catalog entries themselves.
Why teams replace Backstage with NOFire AI.
Every tool in this table is a good product. The difference is the architecture: NOFire AI catalogs from observation. Every other tool catalogs from declaration.
| Capability | NOFire AI | Backstage | Cortex | Compass / Roadie |
|---|---|---|---|---|
| YAML required | None | Yes, for every entity | Yes, service definitions | Yes, via Backstage entities |
| Dependency provenance | Every dependency labeled: runtime (observed) or inferred. Confidence score included. | Declared in YAML, no confidence model | Declared or integration-based, no provenance | Declared, no provenance |
| Service ownership | Observed from deploys, on-call, and contributor history | Manual YAML declaration | Manual + team policies | Jira-linked teams, manual |
| Repository analysis | Agents read README, CHANGELOG, CI/CD pipelines, contributor history | TechDocs, manual authoring | GitHub integration, partial | TechDocs via plugins, manual |
| Readiness scorecard | Scored from actual SLOs, alerts, and incident data | Plugin-based, manual data input | Policy rules, manual input | Jira-based metrics, manual |
| Change timeline | Auto-populated from CI/CD and incident events | Not built in | Via integrations, partial | Via Jira or plugins, partial |
| Dependency graph | Observed from live telemetry | YAML declaration | Partial via integrations | Partial via plugins |
| Blast radius | Calculated from observed call graph | Not available | Not available | Not available |
| Maintenance required | Near zero: agents observe continuously | 2 to 3 engineers, ongoing | Moderate, ongoing | Low (hosted), catalog still goes stale |
One panel. Every layer of service knowledge.
The service detail page in NOFire AI is populated entirely from what agents observe. Nothing is declared manually. Nothing goes stale.
Unlike Backstage, Cortex, and Compass, NOFire AI requires zero YAML, zero manual catalog entries, and zero plugin maintenance.
The checkout service orchestrates the end-to-end purchase flow, coordinating payment processing, inventory validation, and shipping arrangements. It acts as the central transaction coordinator, calling payment, product-catalog, cart, item validation, shipping, currency, email, kafka, and flagd.
2h ago
4d ago
9d ago
19d ago
Live health (SLO / error rate / saturation) arrives with the state engine.
Deterministic facts. LLM-narrated prose.
The catalog structure, dependencies, readiness, and blast radius come from your system, not from an LLM. The LLM only narrates what it cannot invent: prose about what the facts mean.
Every claim cited.
Known mitigations in the wiki cite actual investigation IDs and change event records. If there is no evidence, the section says so. NOFire AI does not fill in gaps.
Provenance on every dependency.
Each dependency in your catalog carries a provenance label: runtime (observed from DNS/L7 call graphs), synthesized (inferred from patterns), or intent (declared). You see exactly how confident the catalog is.
The developer portal AI agents can actually use.
When a human engineer hits a stale catalog entry, they lose 20 minutes. When a coding agent, deployment agent, or incident response agent hits one, it acts on it. The catalog nobody maintains is now the context layer your entire AI stack runs on.
The stale catalog problem just got a lot more expensive.
NOFire AI reads your GitHub repositories directly, including workflow definitions, contributor history, and release tags. Combined with live production signals, the result is a catalog that is accurate enough for both humans and AI systems to rely on.
entity graphcalls: product-catalog, inventory, payments [runtime, 0.9]change events14 rollouts in 90d, 2 scaling eventsprometheus rules3 SLOs, 7 alerting rules [live fetch]metric catalog23 linked metrics, selector definedinvestigations4 incidents, avg resolution 22 minresolutions2 known mitigations [cited: INV-12, INV-23]blast radiusfailure affects: frontend, cart, accounting [pagerank]README.mdgRPC service, 3 downstream consumersEvery layer of service knowledge, observed automatically.
Service ownership
NOFire AI agents trace deploy history, on-call patterns, and contributor activity to assign ownership from evidence, not declarations.
Readiness scorecard
Four binary checks: has owner, has metrics, has alerts, is not a single point of failure. Not a score you enter. A score derived from yes/no facts about your actual system.
Change timeline
Every deploy, rollback, and incident appears on the service timeline as it happens. No one logs it manually.
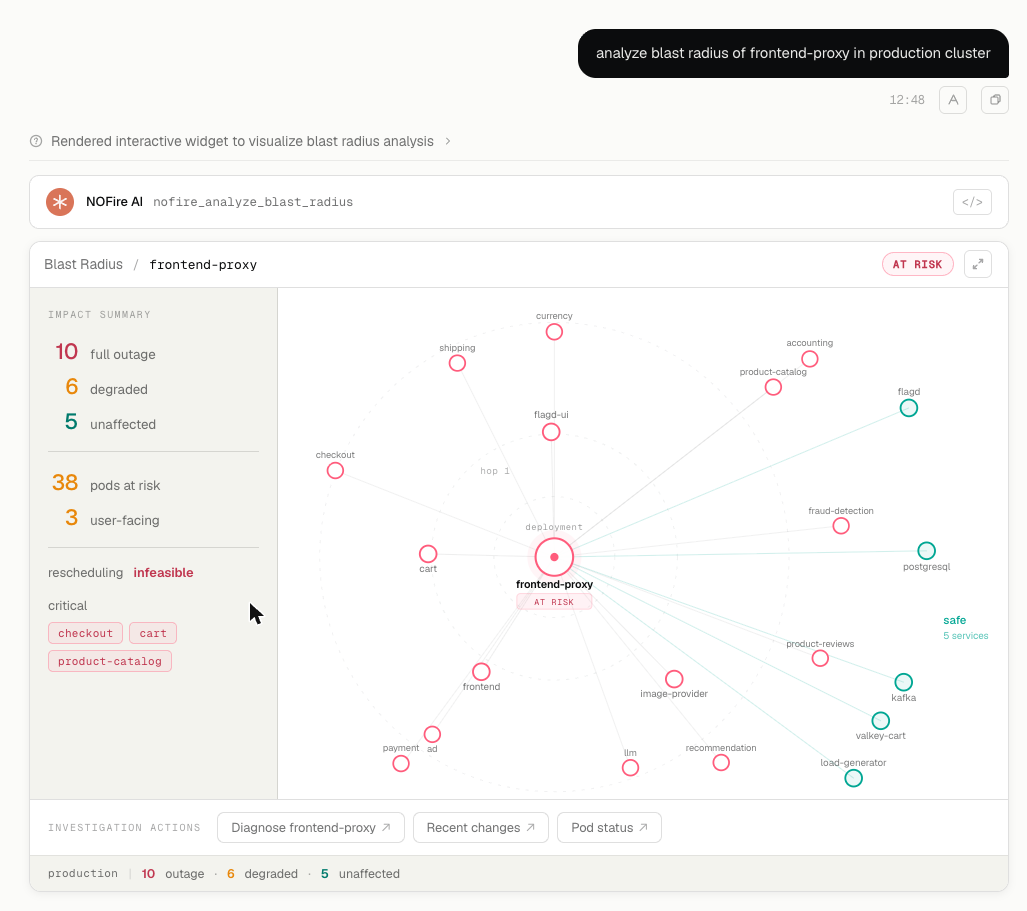
Blast radius
When a service has a problem, you see exactly which downstream services are at risk, calculated from the observed call graph.
Application map
Service dependencies traced from live telemetry. The graph reflects what production is doing right now, not a YAML file from 2022.
Repository knowledge
NOFire AI agents read README files, CHANGELOG entries, contributor graphs, and CI/CD pipeline definitions to distill architectural context automatically.
Runbooks and learnings
Past incident resolutions are captured and surfaced on the service page. The catalog gets smarter after every incident.
Criticality inference
NOFire AI infers service criticality from dependency depth, traffic patterns, and incident blast radius. No tier spreadsheet required.
Connect once. Observe continuously.
Connect your production signals
Prometheus, distributed traces, deploy events, GitHub or GitLab repositories, and on-call integrations. Most teams are connected in under two hours.
Agents observe and synthesize
NOFire AI agents continuously read repos, trace ownership, measure readiness, and calculate blast radius from live production behavior.
Your catalog stays current
You read the catalog. You don't write it. As production changes and code evolves, the catalog changes with them. Automatically.
See what breaks before the incident becomes a crisis.
The blast radius panel shows exactly which services are downstream of the affected service, calculated from the observed call graph. No topology diagrams to maintain. No Slack thread to trace dependencies.
When checkout-service fails, you see that frontend, cart, and accounting are at risk, in seconds, because NOFire AI already traced the call paths from production telemetry.
See how NOFire AI compares to each tool.
Your engineers are maintaining a catalog that is already wrong.
Book a 30-minute session and see your actual service topology, built from what is running in production right now, with no YAML required.
No commitment. Works with Prometheus, Datadog, GitHub, and GitLab.